
Pima Indians Diabetes Classification (with Python)

Use machine learning to predict if a female will be tested positive or not for Diabete?
From the last post, we will continue with the diabetes dataset.
The first 5 rows show that there are many zero value in some columns, because we can’t have biological data with zero, I considered it as Nans.
import numpy as np
import pandas as pd
## Read the file
df = pd.read_csv('pima-indians-diabetes.data.txt', names = ['Number_times_pregnant','PlasmaGlu',
'Dbpressure', 'Tricep_thickness', 'Hour_serum_insulin','Bmi', 'Dpfunction', 'Age', 'Class variable'])
## Read the first 5 rows
df.head()
Here’s the first rows.
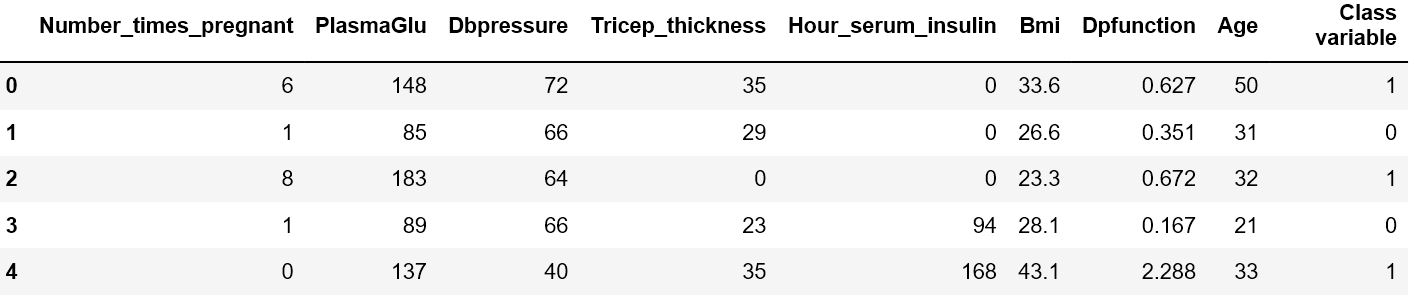
I choose to replace all the 0/nans with the median by each class.
## Imputing nans with median from each class
df1 = df1.fillna(df1.groupby('Class variable').transform('median'))
Here’s the first rows after imputing.
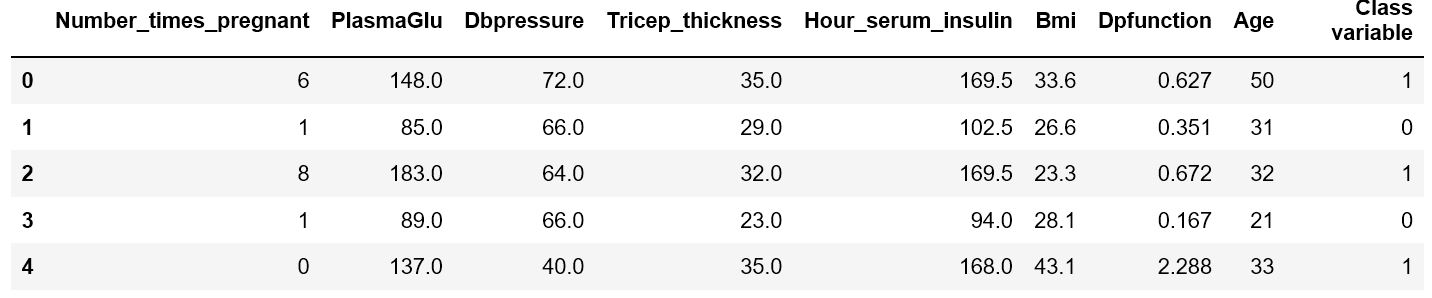
Just to remember, we have 2 classes: 0 and 1. I used five algorithms from scikit learn package: KNeighbors, Random Forest, Gaussian NB, ExtraTrees and DecisionTree. Here is the accuracy on the training set.
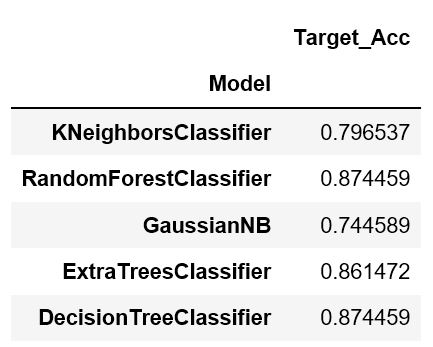
Random forest model and decision tree gave the highest accuracy around 88% and we can have also the most important predictors.
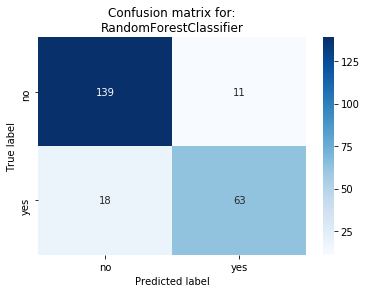
Let’s examine also the confusion matrix. We have:
- True negative (TN) = 139
- True positive (TP) = 63
- False negative (FN) = 18
- False positive (FP) = 11
Because it’s better to predict a person which is negative as positive than a person which is positive as negative, the worse case here would be FN. So, in this case recall is a better metric, let’s calculate it. Recall is, out of the positive class, how many did I correctly predict as positive?
Recall = TP / FN + TP -> 63 / (18+63) which is 0.78
And precision, out of the cases I predicted be positive, how many are really positives?
Precision = TP / FP + TP -> 63 / (11+63) which is 0.85
This is not so good because recall should be higher than precision for this problem.
What about the weight of the 5 most important features?

The most important features to predict diabetes are : 2-Hour serum insulin (mu U/ml), Triceps skin fold thickness (mm) and Plasma glucose concentration a 2 hours in an oral glucose tolerance test. Indeed, these are important parameters to evaluate diabetes.