
Breast Cancer Classification (Python)

Using machine learning to predict the presence of breast cancer?
From the last post, I will continue with the breast cancer dataset from University of Coimbra.
Fortunatly, we don’t have missing values here. So, after some EDA, I used Lasso regression to select the most important predictors. Indeed, as the authors found, resistin, glucose, age and BMI are the most important. data with zero, I considered it as Nans.
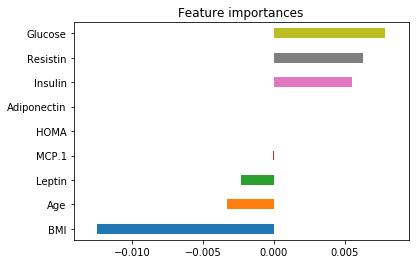
I used the algorithms from the paper: Logistic regression, SVM, Random Forest and others from scikit learn package: KNeighbors, Gaussian NB and DecisionTree. I calculated the recall on the training set which is 70% of the dataset. Here is the result
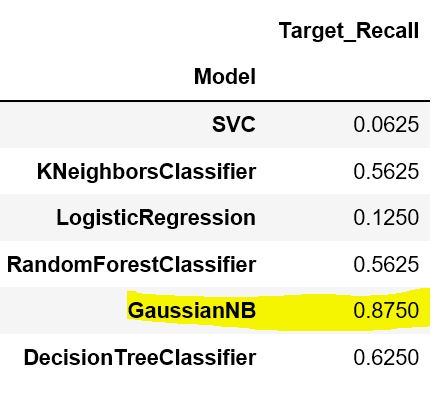
Gaussian NB gave the highest recall/sensitivity of 87.5% which is within the range of [82.2%, 87.5%] on the paper. Compared to the paper SVM did not perform well here. I did not calculate the specificity here, so there much work to do.
What about the ROC curve?
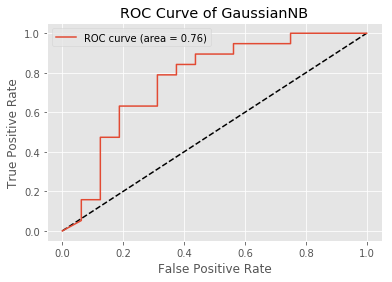
The area under the curve of Gaussian NB is 76, this is less than the one of the paper, there is more feature engineering and tune parameters to do. The most important parameters found where the same of the paper so we are on the right way to increase these metrics.